Catch Quiet Power Users Before They Churn: An Engaged-Then-Cold Playbook for Shopify Apps
A detailed Spreeflo journey for Shopify and e‑commerce apps to detect when previously engaged, high‑value merchants go quiet, trigger internal alerts, send a personal-feeling check‑in, and track risk stages so you can prevent silent, high-MRR churn.
Industry
Niche
Pattern
Loading sequence...
Three Mondays in a row, Elena opened Stripe and saw the same pattern.
A $199/mo store that had been using her Shopify app, CartWizard, for almost a year. High email open rates, dozens of recovery campaigns set up, steady recovered revenue. Then: activity drops off a cliff. Two weeks later, the dreaded app_uninstalled webhook arrives.
No rage email. No “this is too expensive.” Just silence first, churn second.
For CartWizard, those “once-great-now-gone” stores made up a small slice of accounts… but a huge share of churned MRR. They were the merchants who had already proven value, then quietly drifted away while nobody was watching.
The sequence at the top of this page is the whole journey, end to end. It’s built to catch those merchants the moment they go from engaged to cold, alert a human, and send a personal-feeling check‑in before the uninstall happens.
This article walks through that journey node by node for a Shopify or e‑commerce app, and shows how to adapt it to your definition of “engaged”. Underneath it all is one simple idea: if you can capture enough detail on every customer to know when they change state, you can stop leaking lifetime value from preventable churn.
The silent danger: when your best users disappear first
Most churn work focuses on new users who never activate. That matters. But for e‑commerce apps, some of the most painful churn comes from the opposite end:
Merchants who installed months ago
Have real revenue tied to your app
Opened your onboarding and feature announcements
Then suddenly stop opening anything and stop logging in
Those are your power users. Losing them hurts twice: you lose their MRR and the social proof and referrals they might have generated.
The good news: “engaged then cold” is a strong early warning. The better news: you rarely need a big team to act on it. A single founder or CSM with the right automation can jump on these the moment they happen.
That’s what this journey does, using Spreeflo’s Leave Segment trigger, internal alerts, and a targeted email that looks like something you’d write by hand.
Before we get into the trigger, you need one thing set up correctly: your definition of “engaged”.
Step 1: Define “engaged” precisely, not emotionally
Everything in this pattern hinges on a single segment: “Engaged power users”.
If that’s fuzzy, your alerts will either be noisy or too late.
In Spreeflo, you define that once using the segment builder, then reuse it everywhere. For a Shopify or e‑commerce app, an “Engaged” segment might combine:
Email activity:
Email Activity → opened at least 3 times in the last 30 days
Product usage via events (sent from your backend via the Spreeflo API):
Custom Events →
feature_usedtriggered at least 5 times in the last 14 daysPlan or value filters:
Contact Attributes →
planis Pro or aboveContact Attributes →
monthly_mrrgreater than 50
You can express that as:
An outer AND group ensuring “paying and of some value”
An inner OR that says “either they open your emails or they use the app frequently”
The exact numbers aren’t sacred. The point is:
“Engaged” is defined by recent behavior in a time window, not just plan type.
You can explain it in one sentence to your team.
Once that Engaged segment exists, the rest of the playbook hangs off a simple state change:
“Contact is no longer in Engaged.”
That’s when our journey fires.
Step 2: Use a Leave Segment trigger as your early‑warning siren
The first node in the journey is a Leave Segment trigger:
Trigger: Leave Segment
Segment:
Engaged power usersRe-enrollment: ON
Why Leave Segment, not a Custom Event or Criteria Match?
Because the thing you care about is a change in profile state over time, not a single event.
You don’t want alerts on every low‑open week. You want an alert when someone who previously met your “engaged” bar drops below it. The Leave Segment trigger is built for that.
Turning re-enrollment on matters for SaaS:
A merchant might go hot → cold → hot → cold across seasons.
Each “drops out of Engaged” moment is a useful signal.
With re-enrollment enabled, this journey will run every time they leave the Engaged segment (as long as they’re not currently mid‑journey), which is exactly what you want for an ongoing early‑churn monitor.
From here, the path splits into three phases:
Stamp the risk state onto the contact.
Alert a human and send a personal check‑in.
Wait to see what they do next, then tag the outcome.
Step 3: Stamp risk state on the contact
As soon as the trigger fires, the journey updates the contact record so the rest of your system “sees” that risk.
3a. Update Contact Attribute: risk_stage
First action:
Node: Update Contact Attribute
Attribute:
risk_stage(TEXT custom attribute)Update type: Update
Value:
engaged_cold
This is a static literal. Every contact who leaves Engaged gets their risk_stage set to engaged_cold.
Why bother, when you already have tags and segment membership?
Because attributes are:
Filterable everywhere (segments, other journeys, webhooks)
Easy to use in email copy (e.g., “I noticed your account is marked as at‑risk, wanted to check in”)
A clean input for external tools if you send contacts out via Webhook later
3b. Update Contact Attribute: risk_flagged_at
Second action, immediately after:
Node: Update Contact Attribute
Attribute:
risk_flagged_at(TIMESTAMP custom attribute)Update type: Set to now
This writes the current timestamp when the node runs. Later, you’ll use it to answer questions like “How many at-risk engaged users did we flag this month?” in a segment.
3c. Add Tag: engaged-then-cold
Third action:
Node: Add Tag
Tags:
engaged-then-coldForce tag trigger: OFF
The tag makes it easy to:
Pull a quick manual list in support or success
Use “has tag engaged-then-cold” as criteria in other journeys
Visually scan a contact’s history and see the state change
Turning Force tag trigger off means you won’t accidentally re‑fire any Added Tag triggers elsewhere if the tag was already present.
All three of these steps are about capturing detail on every customer so you can speak to each uniquely. You’re enriching the contact record the moment risk appears, instead of keeping that knowledge trapped in your head or a spreadsheet.
Step 4: Notify a human, then send a human‑sounding email
Now that the contact is marked as at‑risk, the journey moves into outreach.
4a. Send Internal Email: “High-value user just went quiet”
Fourth node:
Node: Send Internal Email
Recipients: founder / CSM / small “churn‑watch” list
Send only once: ON
This email is your bat‑signal.
Inside the email builder, you might include:
Contact name, store name, plan
Their
monthly_mrrattribute pulled in via variablesLast
feature_usedevent time, sent in from your app via the Spreeflo APIA direct “View in admin” link with their contact ID
The goal isn’t to create another noisy notification. It’s to surface the subset of at‑risk users who are genuinely worth a manual look.
Because this is an internal email, the pacing rules about sending to the same contact don’t apply. You can send it immediately after the tags and attributes update.
4b. Time Delay: give the human a head start
Next:
Node: Time Delay
Duration: 2 hours
Unit: Hours
This gives your team a small window to act manually if they want to:
A quick Loom video
A personalized note from the founder
A Twitter DM, if that’s in your playbook
For everyone else, the automation will take over after two hours.
4c. Send Email: personal-feeling check‑in
Then, the key customer-facing action:
Node: Send Email
Purpose: founder/CSM-style “I noticed you went quiet” message
Send only once: ON
The content should be short, specific, and clearly written for them:
Acknowledge their past engagement: “You’ve recovered $X with CartWizard over the last few months.”
Call out the change: “I noticed activity has dropped in the last couple of weeks.”
Offer help or a fast path: “If something broke or if setup got confusing, just hit reply and I’ll look at your account personally.”
Because Spreeflo stores contact attributes and event data on one record, you can use things like:
Plan name
Key features they used
Rough recovered revenue or orders processed (if you store that)
to customize the copy and subject. If you want to go further, you can use personalize with AI variables to generate subject lines that pull in that context automatically, while still sounding like a real person.
The key is restraint: this journey sends one customer-facing email at this point, not a multi‑day drip. Your highly engaged merchants don’t need re‑education yet. They need a nudge and an easy reply path.
Step 5: Wait for a response, then branch
After the check‑in email, the journey pauses to see what the contact does.
5a. Wait Condition: re-engage or timeout
Next node:
Node: Wait Condition
Condition: contact is again a member of
Engaged power usersOptionally OR “opened the check‑in email at least once in the last 7 days”
Timeout: 7 days
This behaves like:
If they re‑enter the Engaged segment or engage with the email, move on immediately.
Otherwise, wait up to 7 days, then proceed anyway.
Using Wait Condition rather than a simple Time Delay means the journey reacts as soon as there’s a positive signal, instead of blindly waiting the full week.
5b. If/Else: are they back in Engaged?
Once the wait ends (either by condition or timeout), we branch:
Node: If/Else
Condition: contact is member of segment
Engaged power users
Two paths:
Yes branch: “Recovered”
Else branch: “Still cold”
Everything up to this point is identical for every at‑risk contact. From here, you treat those who came back very differently from those who stayed cold.
Step 6: When they come back, close the loop
On the “Recovered” branch, we keep it light but deliberate.
6a. Add Tag: saved-from-churn
First:
Node: Add Tag
Tags:
saved-from-churn
This gives you a clean flag for future analysis. It also lets you easily thank these people in future campaigns (“merchants we saved from churn last quarter”).
6b. Update Contact Attribute: risk_stage back to healthy
Next:
Node: Update Contact Attribute
Attribute:
risk_stageUpdate type: Update
Value:
healthy
Optional but useful. It resets the high‑level state back to normal, while leaving risk_flagged_at intact as a historical marker.
6c. Send Internal Email: “Good news, they’re back”
Last on this branch:
Node: Send Internal Email
Short note to the same churn‑watch list
Content might look like:
Subject: “Recovered: [Store name] is active again”
Body: quick recap of what changed (segment membership, last feature used)
This is as much for morale as for data: you see which early‑churn interventions actually worked, and you can skim replies to the check‑in email directly in your inbox.
Notice there’s no additional marketing email here. Once someone has re‑engaged, they’ll continue to receive whatever regular lifecycle messages you already send. No need to pile on.
Step 7: When they stay cold, prepare for win‑back
On the “Still cold” branch, the goal isn’t to spam. It’s to clearly mark these contacts for your broader win‑back strategy.
7a. Add Tag: at-risk-high-likelihood-churn
First:
Node: Add Tag
Tags:
at-risk-high-likelihood-churn
This separates them from:
Brand‑new trials who never activated
Mildly inactive users who never qualified as Engaged
You now have a small, well-defined group of “we tried to save them early and it didn’t work” accounts.
7b. Update Contact Attribute: risk_stage = likely_churn
Next:
Node: Update Contact Attribute
Attribute:
risk_stageUpdate type: Update
Value:
likely_churn
This gives your reporting and external systems a clean signal.
From here, you might:
Let a separate, slower win‑back journey pick them up later using a Criteria Match or Join Segment trigger keyed off
risk_stage = likely_churn.Or simply monitor them and let your normal uninstall/offboarding flows handle the rest.
The important part: this journey doesn’t hammer them with more emails. It identifies, alerts, nudges once, then classifies the outcome.
Making the numbers: how to tell if this earns its keep
Two metrics tell you whether this pattern is worth maintaining:
Early‑churn save rate
Retention by intervention timing
Here’s how to get each.
Early-churn save rate
You already record:
risk_flagged_at(timestamp)risk_stagetransitionsTags:
engaged-then-cold,saved-from-churn
Using segments (under the audiences and segments view), you can define:
“Flagged at-risk engaged in last 30 days”:
risk_stageisengaged_coldORlikely_churnrisk_flagged_atis within last 30 days
“Saved from churn in last 30 days”:
Tag contains
saved-from-churnrisk_flagged_atis within last 30 days
Save rate is then:
Saved from churn / Flagged at-risk engaged
Even a modest lift here pays for a low‑priced tool many times over, especially for higher‑tier apps.
Retention by intervention timing
Over time, you can adjust:
How strict your Engaged definition is
How quickly the Leave Segment trigger fires (driven by that segment’s time windows)
How long you wait in the Wait Condition
Use web tracking and analytics plus your own revenue data (synced as attributes via the Spreeflo API) to compare:
3‑month retention for accounts flagged and saved
3‑month retention for accounts that never got flagged but are on similar plans
3‑month retention for accounts flagged but not saved
You’re looking for a story like:
“We save 18% of at‑risk engaged users within seven days, and those saved accounts retain almost as well as never‑at‑risk accounts.”
That’s the kind of number that convinces a skeptical co‑founder this isn’t just more marketing noise. It’s a real plug in a very real LTV leak.
Why this pattern fits founder‑led app teams so well
If you’re running an e‑commerce app with a handful of people, you don’t have a churn ops team. You have a busy founder, maybe a marketer, and a support inbox that’s already full.
This journey leans into that reality:
It uses data you already have: email engagement and product usage.
It runs continuously in the background via campaigns and journeys.
It surfaces only the most meaningful state change: “engaged then cold”.
It asks for one simple human action: reply to the people who care enough to respond.
Most businesses in your position are leaving customer lifetime value on the table by not nurturing engagement once it starts to slip. The difference between you and them is whether you treat engagement as an asset you track and act on, or just a nice‑to‑have dashboard number.
Build this once, wire it to your definition of “engaged”, and let it run. When you next see a high‑MRR store drifting towards silence, you won’t find out from an uninstall email. You’ll already be in their inbox, asking what they need.
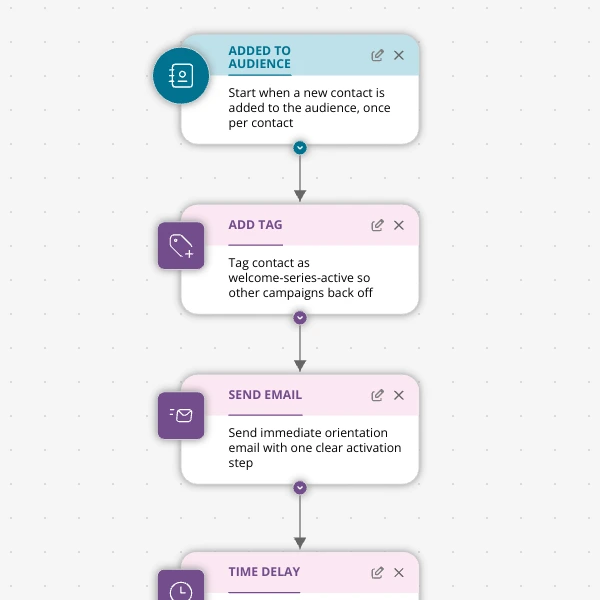
The Shopify app welcome series that turns installs into income
A step-by-step Shopify app welcome email journey for tools like CartSpark, showing how to turn new installs into activated, retained merchants using Spreeflo journeys, tags, and behavioral triggers so fewer trials quietly churn and more trials convert.
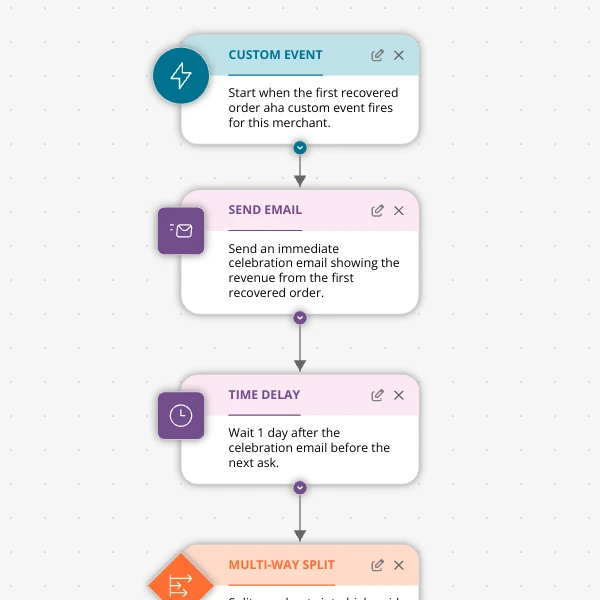
The Aha-Moment Playbook For Shopify Apps: Turn One Magic Action Into Months Of Revenue
A node-by-node playbook for Shopify and e‑commerce apps to center their lifecycle on one aha-moment custom event in Spreeflo, celebrate it, segment merchants by profile and engagement, and turn first recovered value into lasting revenue and retention.
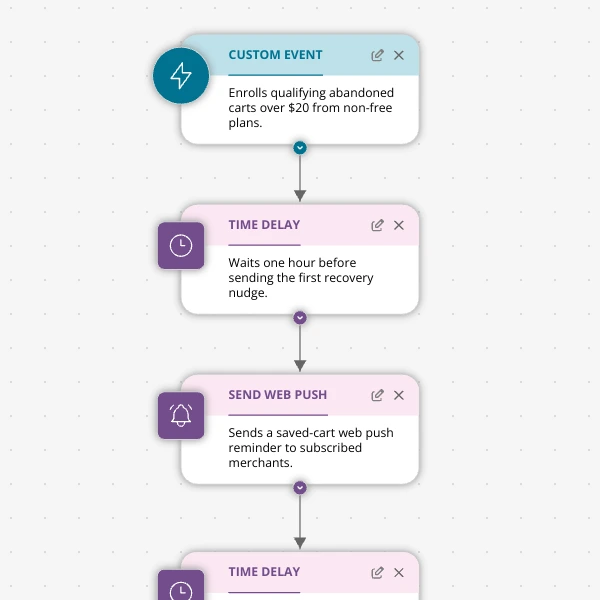
Stop Letting High‑Intent Carts Die: A 3‑Email Recovery Journey for Shopify Apps
A detailed, node-by-node walkthrough of a three-email (plus optional web push) cart-abandonment recovery journey for Shopify apps in Spreeflo, showing how to trigger events, branch on behavior, tag outcomes, and measure recovered carts and revenue.
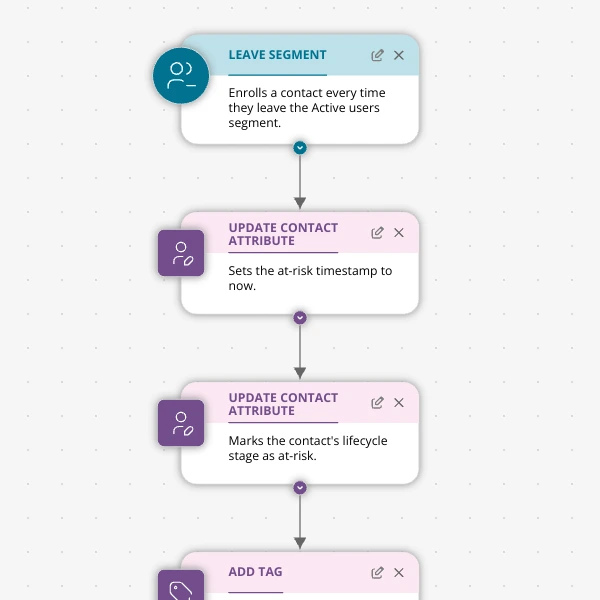
When Active Users Go Dark: A 4‑Touch Win‑Back Journey For Your Shopify App
A detailed, node-by-node Spreeflo journey for winning back previously active Shopify app users who stop engaging, using segment-based triggers, conditional logic, and a four-touch email plus internal alert sequence to recover usage and MRR.