Let Your Billing Events Run Your Emails (Not Your Team)
A detailed playbook for wiring Stripe or Shopify Billing (and other backend events) into Spreeflo journeys so failed payments and similar triggers automatically send targeted emails, update tags and attributes, and coordinate account changes—without manual intervention.
Industry
Niche
Pattern
Loading sequence...
The Stripe email hits your inbox at 3:02 a.m.: “invoice.payment_failed.”
You know exactly what happens next. The merchant’s checkout flows are still working, their store is still using your Shopify app, and somewhere between “I’ll update that card later” and “whoops, forgot,” your future ARR is slipping away. If you’re like a lot of app founders, you either ignore it or copy‑paste a manual email from a canned response when you remember.
Meanwhile, those billing and product events are already flowing through your backend in real time. They’re just not talking to your marketing automation.
The sequence at the top of this page is the whole journey, end to end. A billing event from your backend hits Spreeflo as a custom event, and a real, personalized email goes out without anyone on your team lifting a finger. Then the journey watches for a successful charge and adapts the messaging accordingly.
In this playbook, we’ll walk through that journey as if you were wiring it into a Shopify app like CartWizard: Stripe or Shopify Billing on one side, Spreeflo on the other. Same pattern works if your trigger is a shipping update, a support ticket, or a feature flag flip.
Why external events are the best triggers you’re not using
As an e‑commerce app developer, you already live in webhooks:
Stripe’s
invoice.payment_failed,invoice.payment_succeededShopify’s
app/uninstalled,orders/createYour own app’s
usage_threshold_reached,feature_used
You probably feed these into your backend and maybe a Slack channel. But most teams stop there. Marketing emails get written separately, often on a schedule, with only a vague sense of who saw what in the product.
That’s the leak.
Those external events are the cleanest, richest signals you’ll ever get:
They’re specific to a single account.
They come with data you care about (plan, MRR, feature flags, geography).
They show up in real time.
Spreeflo’s angle is simple: treat those events as first‑class triggers. Your backend calls the Spreeflo API or Spreeflo.track from the JS SDK, that becomes a Custom Event, and a journey picks it up immediately.
You capture more detail on every customer, then use it to speak to each one uniquely. And because the journey runs on its own, a two‑to‑ten‑person team gets enterprise‑grade automation without needing an enterprise‑size marketing org.
What this journey does in plain language
Before we zoom into nodes, here’s what the sequence at the top of this page does for CartWizard:
Your billing backend receives a failed‑payment webhook.
It forwards a
payment_failedevent into Spreeflo with customer and invoice details.Spreeflo’s Custom Event trigger enrolls that contact in a journey.
The journey:
- Tags the contact as “billing‑at‑risk”.
- Marks when the failure happened and increments a counter.
- Sends a precise “update your card” email.
- Waits a set period to see if apayment_succeededevent arrives.
- Branches based on success or no success.
- Sends different follow‑up emails and updates tags/attributes accordingly.
- Optionally calls a Webhook action back into your app to pause or downgrade the account.
Let’s walk that node by node and talk about why it’s built that way, and what to tweak for your own stack.
1. Custom Event trigger: listening to your billing backend
At the very top of the journey is a Custom Event trigger configured for an event name like payment_failed.
On your side, that means:
Your billing system (Stripe, Shopify Billing, Chargebee) fires a webhook to your backend.
After you’ve done your normal checks, your backend calls the Spreeflo API or a server‑side wrapper with something equivalent to
Spreeflo.track("payment_failed", eventData, attributes).
The trigger is set up roughly like:
Event name:
payment_failedProperty conditions: optional. For example, only trigger the sequence when:
-planis"pro"or"plus", or
-amountgreater than20.
Inside the trigger, you turn Re-enrollment on.
Why re‑enrollment should be on here:
A customer can have more than one failed payment over their lifetime.
You want the journey to fire again for a second failure, but only after they’ve exited the previous run.
Spreeflo’s mid‑journey lock ensures they never run through two copies in parallel, which keeps your messaging sane.
If you also want a cancellation‑specific path (for events like subscription_canceled), you can drop a second Custom Event trigger into the same journey with isReEnrollment=false (cancellations should rarely need loops) and give it its own downstream branch.
2. Tagging the account as at‑risk (Add Tag)
The first node after the trigger is an Add Tag action.
Configuration:
Tags:
billing-at-riskForce tag trigger: off (you don’t need to fire Added Tag triggers every time for this tag).
Why it’s here:
Tags give you an instant, human‑readable view of account state across tools.
You can later build a segment of all
billing-at-riskcontacts in the segment builder and use that for reporting, campaigns, or support workflows.If you’re piping data into a support tool, this tag becomes a simple flag: “handle with more care; payment is failing.”
You could stack additional tags here, for example plan-pro or plan-enterprise, if you want downstream journeys to branch on plan.
3. Capture context with attributes (Update Contact Attribute)
Next, the journey writes a bit of structured data to the contact using Update Contact Attribute actions.
Typical attributes to maintain:
last_payment_failed_at(TIMESTAMP)
- Update type:SET_NOW
- Why: gives you an easy way to filter “anyone whose last failure was more than X days ago” or “within the last 24 hours.”billing_failure_count(NUMBER)
- Update type:INCREMENT
- New value:1
- Why: lets you distinguish someone who has one temporary hiccup from a chronically failing account.
Because Update Contact Attribute uses static literals (except for “Set to now”), you predefine the increment amount, names, and semantics. Your backend should still be the ultimate source of truth for billing state, but these attributes are your marketing‑facing snapshot.
This is where Brand Message 1 shows up in practice: you’re not just sending “a failed payment email.” You’ve got attributes that make each contact’s situation queryable and targetable.
4. The first email: precise, immediate, and self‑serve
Now the journey hits the first Send Email node.
Configuration details:
Template: a “payment failed” email built with the email builder.
From: your standard support or billing identity.
Send only once: on. You don’t want the same step re‑firing if a contact somehow re‑enters this node later.
What goes in this email:
Clear description of the problem:
- “We tried to charge $49 for your CartWizard subscription and your bank declined the payment.”Direct link to your billing page inside the app.
Lightweight reassurance about data safety and continuity.
Optional microcopy based on plan or currency, using personalization variables.
Because the event is real time, your trigger latency is basically “API call in, email out.” To keep that low:
Send the
payment_failedevent as soon as you know the failure is definitive.Avoid running long backend logic before calling Spreeflo.
From a customer’s perspective, the experience feels like your app and email are one system, not separate worlds.
5. Give them time: Time Delay before you start checking
After the first email, insert a Time Delay:
Delay value:
2Delay unit:
day(s)
Why not check immediately?
Customers don’t always see or act on email instantly.
Payment issues sometimes clear automatically (new card on file, bank anti‑fraud logic, etc.).
Giving a short buffer respects their attention and prevents multiple “nag” emails in quick succession.
The message‑pacing rule matters here too: you never want back‑to‑back Send Email nodes without a Time Delay or Wait Condition between them. This delay satisfies that and keeps you on the right side of inbox fatigue.
6. Wait for success, but don’t stall forever (Wait Condition)
Next, use a Wait Condition to watch for a successful payment.
Configuration:
Condition: in the embedded segment builder, define:
- Custom Events →payment_succeeded→ triggeredAT_LEAST1 timein the last7 days.Timeout duration:
5days, unitday(s).
What this does:
If a
payment_succeededevent arrives and makes the condition true, the contact moves on immediately.If nothing happens for 5 days, the timeout expires and they also move on.
In both cases, they go to the same next node. You haven’t branched yet; you’ve just controlled timing. That keeps the logic simple and avoids contacts sitting in limbo forever because an event never came.
7. Branch based on outcome (If/Else)
Right after the wait, add an If/Else process node.
Use the same condition as above:
Condition: Custom Events →
payment_succeeded→AT_LEAST1 timein the last7 days.
Now:
“Then” branch: payment issue resolved.
“Else” branch: still unpaid, or success happened outside your time window.
This pattern (Wait Condition for timing, then If/Else for branching) is cleaner than trying to cram timing and outcome into a single construct. It also keeps every branch honest in terms of email pacing, because the Wait Condition fulfills the “no back‑to‑back sends” requirement.
8. The “resolved” path: clear the flags and close the loop
On the “Then” branch (payment succeeded), the sequence does three things:
Remove Tag
- Tags:billing-at-risk
- Force tag trigger: off.
- Why: once the issue is fixed, you don’t want this contact showing up in at‑risk reports or segments.Optional Update Contact Attribute
- Attribute:last_payment_succeeded_at(TIMESTAMP)
- Update type:SET_NOW.
- Why: future journeys (like VIP recognition or tenure‑based perks) can query both failure and success timestamps.Send Email — “You’re all set”
- Friendly confirmation that their subscription is back in good standing.
- Quick recap of what will happen next (no service interruption, receipts, etc.).
- A small upsell or feature reminder never hurts, but keep the main message reassurance.
Because there’s a Wait Condition between the first and second email, you’re still within good pacing. Some customers will get this “you’re all set” email within hours, others after a couple of days, but no one sees two billing emails stacked back‑to‑back.
9. The “still failing” path: escalation without drama
On the “Else” branch (no successful payment detected), you shift from reminder to consequence.
Typical steps:
Send Email — “We’ll have to pause your account”
- Spell out the timeline and impact:
- How many days until pause or downgrade.
- What features will stop working.
- Make the billing link impossible to miss.Time Delay
- Delay value:3, unit:day(s).
- Gives them one final window to act.Optional second If/Else
- Re‑check forpayment_succeededusing the same Custom Event condition.
- “Then” branch: they rescued themselves in time → go to the “resolved” path or similar.
- “Else” branch: time to sync with your product backend.Webhook action back into your app
- Webhook URL: a secure endpoint your app exposes for “pause subscription” or “limit features.”
- Method:POST.
- Contact fields: either all attributes or a curated set that includes email and plan.
- Authentication: API key or bearer token, configured in the node.
Using a Webhook action here is where the pattern becomes true cross‑system automation. Your backend’s billing logic triggers the journey via custom events; the journey, in turn, pushes a structured “take action on this account” payload back to your app when escalation is warranted.
No manual CSV exports, no “remember to pause this user” Trello cards. Just an event in, decisioning, and a clear outcome.
10. Measuring if this actually works
Three metrics matter most for this pattern: trigger latency, delivery success, and data completeness.
Trigger latency Roughly: time between event in your billing system and email delivered.
- Check the timestamp you send in the event payload against Spreeflo’s email activity timestamps in segments or analytics.
- If you see long gaps, the usual culprits are:
- Delayed or batched API calls from your backend.
- Over‑complicated branching that holds contacts in waits longer than intended.Delivery success You want as close to 100% as you can get for this kind of transactional‑ish email.
- Use Email Activity filters in the segment builder to build a segment like “was not sent” or “did not deliver” for that template.
- Fix bad addresses at the source and consider gating product signup more tightly if you see a lot of failures.Data completeness Every missing piece of data is a weaker email for that contact.
- Audit a sample ofpayment_failedevents in your backend and in Spreeflo to make sure:
- The right email is associated with the event.
- Attributes like plan, currency, and MRR are present where you expect them.
- If you rely on attributes in your copy or logic, ensure your backend is also callingSpreeflo.identifyto upsert those on the contact, not just sending them as event properties.
When this is dialed in, the revenue impact is very direct: fewer involuntary churns, less manual work, and less time your app spends in a weird “using us for free” limbo after payment fails.
Variations you’ll probably want to build next
Once you have payment_failed wired, the same pattern extends cleanly:
Support signals: trigger a journey on
support_ticket_openedwith certain tags, then nudge for feedback aftersupport_ticket_closed.Usage thresholds: send an email when
usage_threshold_reachedon a key feature, using web tracking and analytics or your own backend events to know when someone hits that edge.Shipping or fulfillment: if your app handles post‑purchase flows, trigger journeys on
order_shipped,order_delivered, orreturn_initiatedto keep merchants in the loop.
All of them rely on the same core pattern: external event in, Custom Event trigger, smart branching, and channel‑appropriate Send Email nodes in a journey that runs forever without you babysitting it.
Why this pattern is pure leverage for small app teams
Founder‑led SaaS businesses win by building systems once and letting them compound, not by answering more tickets or writing more one‑off emails.
An external‑event journey like this turns the thing you already have—high‑fidelity signals flowing through your billing and product systems—into targeted communication at exactly the right moment. Every contact who hits the journey is on their own path, with tags and attributes that reflect their actual situation.
You capture detail on every customer and speak to each uniquely, but you configure it once, in an afternoon, instead of handling every edge case manually.
For a Shopify app sitting somewhere between $10k and $300k MRR, that’s the kind of automation that earns its line item: fewer churned accounts, more proactive saves, and a team that gets to spend its time shipping product, not reacting to billing emails.
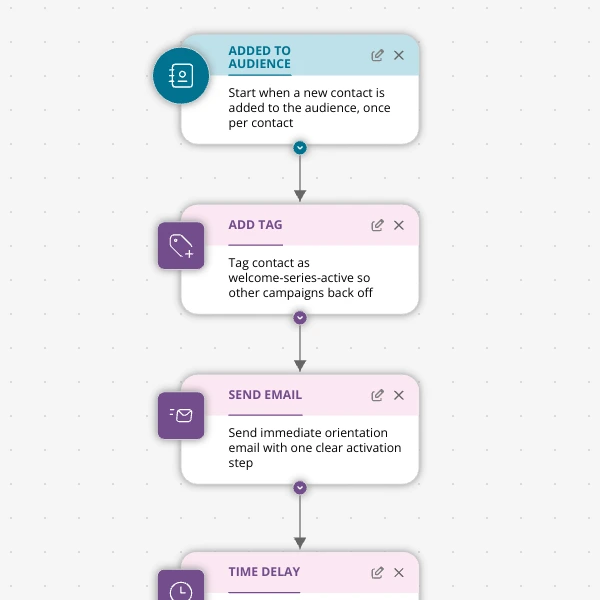
The Shopify app welcome series that turns installs into income
A step-by-step Shopify app welcome email journey for tools like CartSpark, showing how to turn new installs into activated, retained merchants using Spreeflo journeys, tags, and behavioral triggers so fewer trials quietly churn and more trials convert.
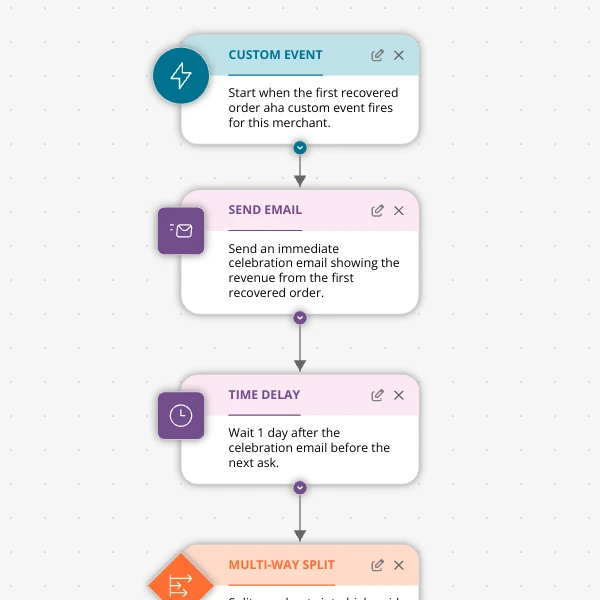
The Aha-Moment Playbook For Shopify Apps: Turn One Magic Action Into Months Of Revenue
A node-by-node playbook for Shopify and e‑commerce apps to center their lifecycle on one aha-moment custom event in Spreeflo, celebrate it, segment merchants by profile and engagement, and turn first recovered value into lasting revenue and retention.
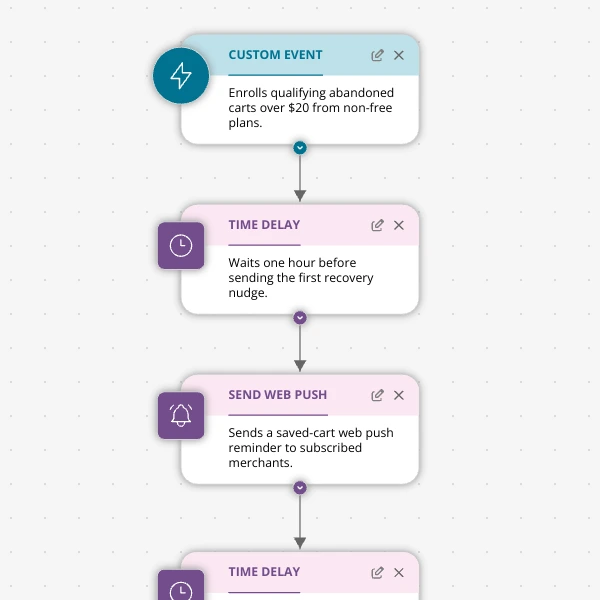
Stop Letting High‑Intent Carts Die: A 3‑Email Recovery Journey for Shopify Apps
A detailed, node-by-node walkthrough of a three-email (plus optional web push) cart-abandonment recovery journey for Shopify apps in Spreeflo, showing how to trigger events, branch on behavior, tag outcomes, and measure recovered carts and revenue.
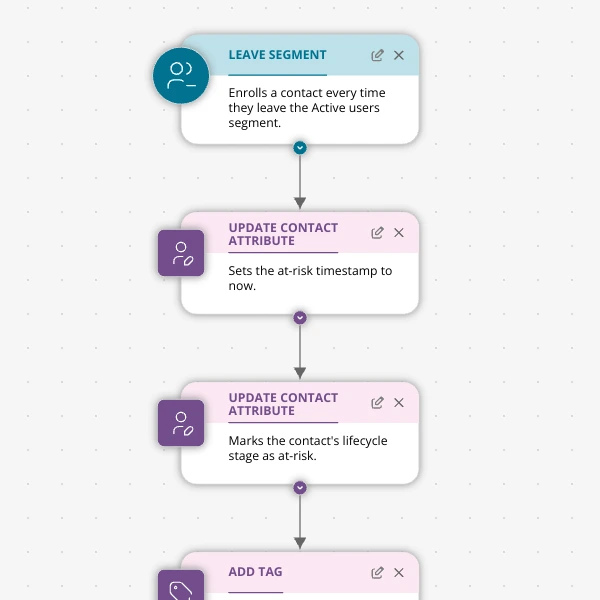
When Active Users Go Dark: A 4‑Touch Win‑Back Journey For Your Shopify App
A detailed, node-by-node Spreeflo journey for winning back previously active Shopify app users who stop engaging, using segment-based triggers, conditional logic, and a four-touch email plus internal alert sequence to recover usage and MRR.