Stop Silent Churn: A Health-Score Alert Journey for Shopify Apps
This playbook shows Shopify app teams how to turn health-score drops into automated internal alerts and personalized merchant check-ins using Spreeflo, so they can intervene early, rescue at-risk stores, and reduce silent churn.
Industry
Niche
Pattern
Loading sequence...
The merchant doesn’t rage-quit.
They don’t send an angry email.
They just quietly uninstall your app at 10:42pm on a Tuesday, three weeks after their usage started dropping. Your dashboard shows the health score slide from 78 to 42 to 19. You see it the next morning, shrug, and move on. Another “natural” churn.
For CartWizard, a cart recovery Shopify app doing around $90k MRR, this pattern was costing them roughly 8–10 stores a month. They _had_ a health score. They even had a “red accounts” dashboard. What they didn’t have was a reliable way to turn that signal into a save attempt in the tiny window before a merchant gave up.
The sequence at the top of this page is the whole journey, end to end. It takes a health-score dip and turns it into two coordinated actions: an internal alert to your team and a timely, human check‑in email to the merchant.
This playbook walks through that journey step by step using Spreeflo, from defining “at-risk” to routing alerts, so that:
Your team hears about trouble while there’s still time to help.
Merchants get a relevant, empathetic email based on their actual usage.
You plug one of the biggest lifetime-value leaks in a Shopify app business: silent churn.
Why a health score without routing doesn’t move your MRR
Most SaaS apps in your revenue band already track _something_ like a health score:
Recent logins
Key feature usage (campaigns sent, reports viewed, orders synced)
Support tickets
Plan type / MRR
You might already stuff this into an internal table and maybe surface a color-coded row in a dashboard.
The problem: a dashboard is passive. Your team has to remember to check it, interpret the risk, and then decide what to do. That doesn’t survive real life when:
Your CS “team” is one founder juggling support, roadmap, and partnerships.
Churn-risk changes daily as merchants go through seasonal swings.
You only notice patterns when MRR is already down for the month.
A health-score alert journey makes the score actionable. It converts “health_score just fell below 50” into:
An immediate, context-rich internal email.
A carefully timed, personalized check‑in to the merchant if they haven’t already recovered.
That’s how founder-led products win: not by adding headcount, but by wiring detailed customer data into automations that run every day on their behalf.
What this journey does when an account goes red
At a high level, the journey in the sequence at the top of this page does this:
Watches for at-risk accounts: When a contact’s health score drops below a threshold (e.g. 50) and they’re not already in an at-risk flow, they enter the journey via a Criteria Match trigger.
Flags the contact as at-risk in your data: Tags and attributes are updated so you and your systems know this account is on the radar.
Alerts your team immediately: A Send Internal Email node pings whoever owns success for that account, with context.
Gives the account a short window to self-recover: A Time Delay and If/Else check see whether their usage bounces back.
Reaches out to the merchant: If they’re still struggling, they get a personalized check‑in email with a specific next step.
Monitors for recovery: A Wait Condition watches for improvement for a few days.
Escalates or closes the loop: Based on what happens, the journey either tags the account as “rescued” and resets, or marks it as “likely-to-churn” and sends a final internal alert.
Let’s walk it node by node and look at how you’d adapt each piece for your own Shopify app.
Step 1: Define “at-risk” in your data layer
Before you touch automation, you need a simple, explicit health definition.
Most Shopify apps end up with something like:
health_score(NUMBER contact attribute, 0–100)Inputs: logins in last X days, key feature events, plan size, support sentiment, etc.
You calculate this inside your app or data warehouse, then write the latest value onto the Spreeflo contact record whenever it changes, using the Spreeflo API in your backend.
That single attribute is what powers the Criteria Match trigger and downstream conditions. The finer-grained your inputs, the more accurately you can speak to each merchant’s situation.
Brand message in action: you’re not sending a generic “you okay?” blast. You’re reacting to a specific risk level on a specific store.
Step 2: Criteria Match trigger — catching the drop
In Spreeflo, this is a Journey, not a Campaign, because it runs continuously and reacts whenever an account becomes at-risk. You create it from the campaigns and journeys view.
The entry point is a Criteria Match trigger with:
Re-enrollment: turned on. Accounts might recover and then become at-risk again later. You want the journey to fire each time that happens.
Criteria (using the segment builder):
Contact attribute
health_score_less than_ 50Email subscription status _is_ Subscribed (so you’re allowed to email them)
Contact is _not_ tagged with
at-risk(we’ll add this tag inside the journey; it prevents the same drop from enrolling them multiple times).
That last line is important. Without it, a noisy scoring job that fluctuates around 50 could try to enroll the same account repeatedly. Using tags as a guardrail is a simple, durable pattern.
Why Criteria Match instead of Join Segment? Because the health-score logic is specific to this journey. There’s no need to maintain a separate saved segment unless you’re also analyzing or reporting on at-risk accounts elsewhere.
Step 3: Tag and timestamp the risk
Once the trigger fires, the first few nodes simply make the risk visible and queryable everywhere else:
1. Add Tag
Tags:
at-riskForce tag trigger: off
This tag becomes the flag you use across Spreeflo for “currently under CS watch.” It also blocks re-entry until you remove it later.
2. Update Contact Attribute — status
Attribute:
health_status(TEXT)Update type: Update
Value:
"at-risk"
This gives you a human-readable state you can show in internal tools or use for additional segmentation.
3. Update Contact Attribute — last drop timestamp
Attribute:
last_health_drop_at(TIMESTAMP)Update type: Set to now
Now you can answer questions like “how many days since they first became at-risk?” inside other journeys or reports.
None of this talks to the merchant yet. It’s all about capturing detail on every account so you can route and respond intelligently.
Step 4: Internal alert to whoever can actually save the account
Next comes the Send Internal Email node.
Configuration-wise:
Choose the sender identity that makes sense for internal alerts (often the founder’s email).
Point it at a distribution list or single owner (e.g. success@yourapp.com or the founder’s inbox).
Use a template that pulls in key context from the contact record:
- Store name
- Plan and MRR
- Current health score
- Last login date
- Last key feature used
The goal isn’t just “FYI, this account looks bad.” It’s to answer, in one glance: “Is this worth 15 minutes of my time today?”
Because internal alerts don’t go to the customer, you don’t have to worry about pacing here. This email can fire immediately after the trigger and attribute updates.
You’ve just improved “time-to-save action” from days (or never) to minutes, without anyone refreshing a dashboard.
Step 5: Give them a short window to self-recover
Plenty of Shopify merchants go through normal quiet periods: they’re between campaigns, changing themes, or just busy.
Hammering them with a “you look at-risk” email the moment their score crosses 49 can backfire. So the journey adds:
A Time Delay of, say, 2 hours.
Followed by an If/Else node that checks whether they already bounced back.
That If/Else uses the segment builder with a simple condition:
“Contact attribute
health_scoregreater than 50”
If the answer is yes, they go down the “recovered” branch. If no, they continue into the external check‑in path.
Why only 2 hours? Because you already sent an internal alert. If your team wants to take a deeper look or send a fully manual, personalized message to a high-MRR store, they can. But you’re not holding the automation back for days, which would eat into your save window.
Step 6: Early recovery branch — quietly reset the account
For the “recovered” branch of the If/Else:
1. Remove Tag
Tags:
at-risk
2. Update Contact Attribute — status back to healthy
Attribute:
health_statusValue:
"healthy"
You might add a lightweight Send Internal Email here as well (“Good news: [Store]’s health is back above 50. No customer email sent.”). That reassures whoever saw the first alert that things resolved on their own.
Notice what you _don’t_ do: email the merchant. They never see the wiring here. Their usage dipped, then recovered. You watched, you recorded it, and you moved on.
Step 7: At-risk branch — send a focused, personal check‑in
For accounts that are still below threshold after the delay, the journey continues into the contact-facing half.
1. Send Email — “Health check‑in #1”
This is a normal marketing-style email, sent to the contact’s email address.
Inside the node, you:
Pick or build the template using the email builder.
Use “send this email only once per contact” (so if they re-enter the journey months later, they don’t see the exact same template again).
Personalize copy with what you know:
“We noticed you haven’t launched a campaign with CartWizard in the last 10 days.”
“Your abandoned-cart recovery has been paused, and we’d love to help you get it back online.”
The CTA should be brutally simple: book a 15-minute call, reply to the email, or click a “fix my setup” checklist.
2. Wait Condition — watch for recovery, don’t nag
Right after the email, add a Wait Condition with:
Condition: health has recovered, e.g. contact attribute
health_score greater than 50
(Optionally OR “Custom eventkey_feature_usedtriggered at least 1 time in the last 3 days” if you’re tracking features via web tracking and analytics.)Timeout: 3 days
If they recover before the timeout, they move on as soon as the condition is true. If not, they move on when the 3 days are up.
This node does two jobs at once:
It spaces your messaging: there is always at least this wait between Email #1 and any follow-up.
It encodes what “success” looks like after the check‑in (higher health or meaningful activity).
Step 8: Branch again based on what happened
After the Wait Condition, add another If/Else node with the same “recovered?” condition.
Now you have two paths.
8a. Recovered after the check‑in
This is the group you genuinely “saved.”
Typical actions:
1. Remove Tag
at-risk
2. Add Tag
rescued(optional, but helpful for reporting)
3. Update Contact Attribute
health_statusto"healthy"
4. Send Internal Email
“Saved: [Store] recovered after check‑in. Current health score: 71.”
This gives you a concrete cohort to track over time: how many at-risk accounts recovered after this journey existed vs before.
8b. Still at-risk after 3 days
This is the group that didn’t respond, didn’t use key features, and is still scoring low.
On this branch:
1. Send Email — “Health check‑in #2 (last call)”
Because there was already a Wait Condition in between, you stay within good pacing. This email can be more direct:
Offer to pause billing.
Ask if they’d like to uninstall and get a short exit survey.
Share a single, opinionated recommendation tailored to their use case.
2. Add Tag
likely-churn
3. Remove Tag
at-risk(so they can re-enter in the future if they stick around but stay unhealthy)
4. Send Internal Email
“Escalate: [Store] still below 50 after two check‑ins. Consider personal outreach or marking as high churn risk.”
This path is about clarity. It doesn’t save everyone, but it makes sure the ones who are sliding away don’t do it silently.
Step 9: Make re-enrollment safe and meaningful
Remember that the Criteria Match trigger has re-enrollment turned on. That’s what lets the same store run through this journey again a few months later if they go red again.
The combination of:
Filtering out contacts tagged
at-riskat the trigger, andRemoving that tag on both exit branches
…ensures that:
You don’t process the same drop twice in parallel.
You _do_ process a new, independent risk event in the future.
This is how you keep long-term retention work on autopilot instead of as a one-off “we built a playbook in Q2” project that silently decays.
What to measure once this is live
A journey like this should earn its shelf space. The big three metrics to watch:
1. Save rate
Among accounts that enter this journey, what percentage:
Still have your app installed 30 / 60 / 90 days later?
Moved their health score back above threshold?
Compare that to your pre-journey baseline.
2. Time-to-save action
How long between “health score dropped below 50” and:
Internal alert sent
First customer email sent
With this journey, both should be measured in minutes or hours, not days.
3. Churn reduction in the at-risk cohort
You won’t fix churn for your entire app with this one playbook. But for the specific slice of stores that enter it, you should see a visible dip in churn and a rise in lifetime value.
Because Spreeflo doesn’t charge for non-marketing contacts, you can safely track health scores and internal alerts across your whole user base, then only pay for the merchants you’re actively emailing through journeys like this. That alignment matters when you’re trying to keep tool costs sane relative to MRR.
Bringing it back to the bigger game
Health scores don’t save customers. People do.
What this journey gives you is the connective tissue between those two facts:
It captures detailed, behavioral signals about each store.
It uses that detail to speak uniquely to accounts who are wobbling.
It keeps engagement going during the exact window where a bit of help can turn a future churn into a long-term customer.
Most Shopify apps bleed lifetime value not because their features are bad, but because they let accounts quietly decay without context or contact. Wiring a health-score alert journey into Spreeflo is how a small, founder-led team fights that trend without adding more humans.
You build it once. It runs every day. And every time a merchant rolls back from 42 to 72 instead of uninstalling, you’ll be glad it does.
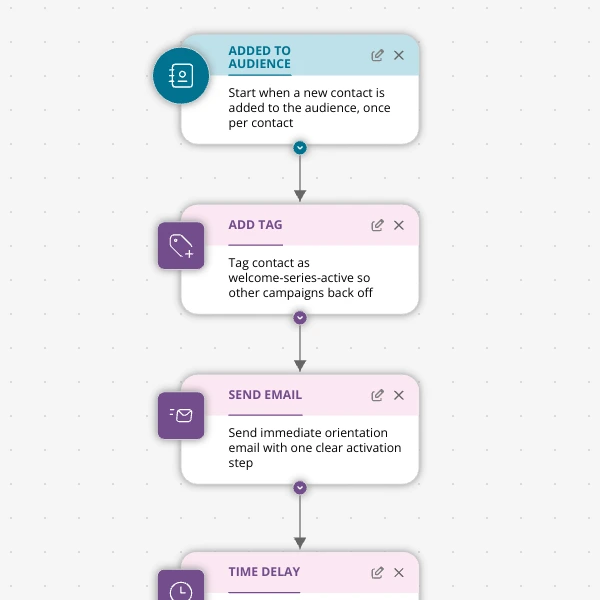
The Shopify app welcome series that turns installs into income
A step-by-step Shopify app welcome email journey for tools like CartSpark, showing how to turn new installs into activated, retained merchants using Spreeflo journeys, tags, and behavioral triggers so fewer trials quietly churn and more trials convert.
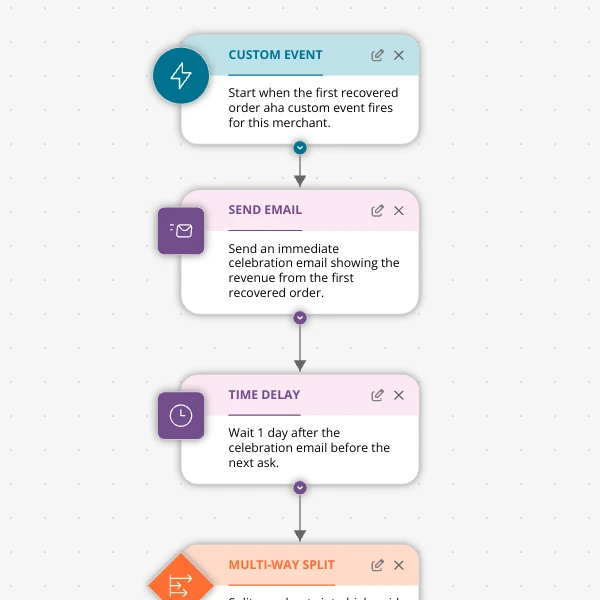
The Aha-Moment Playbook For Shopify Apps: Turn One Magic Action Into Months Of Revenue
A node-by-node playbook for Shopify and e‑commerce apps to center their lifecycle on one aha-moment custom event in Spreeflo, celebrate it, segment merchants by profile and engagement, and turn first recovered value into lasting revenue and retention.
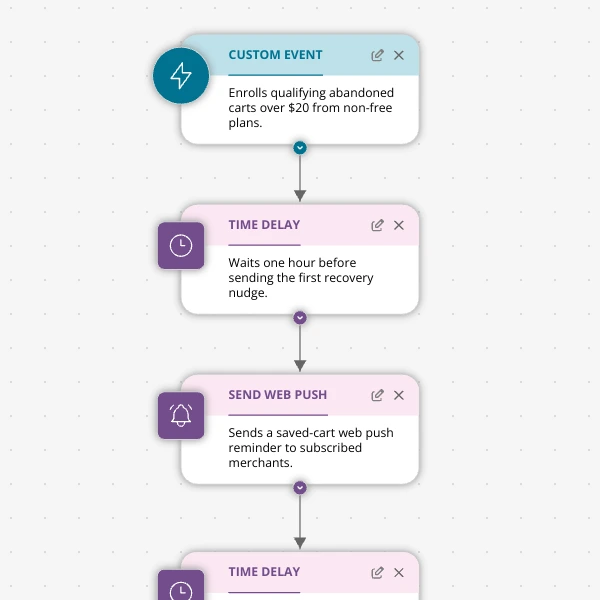
Stop Letting High‑Intent Carts Die: A 3‑Email Recovery Journey for Shopify Apps
A detailed, node-by-node walkthrough of a three-email (plus optional web push) cart-abandonment recovery journey for Shopify apps in Spreeflo, showing how to trigger events, branch on behavior, tag outcomes, and measure recovered carts and revenue.
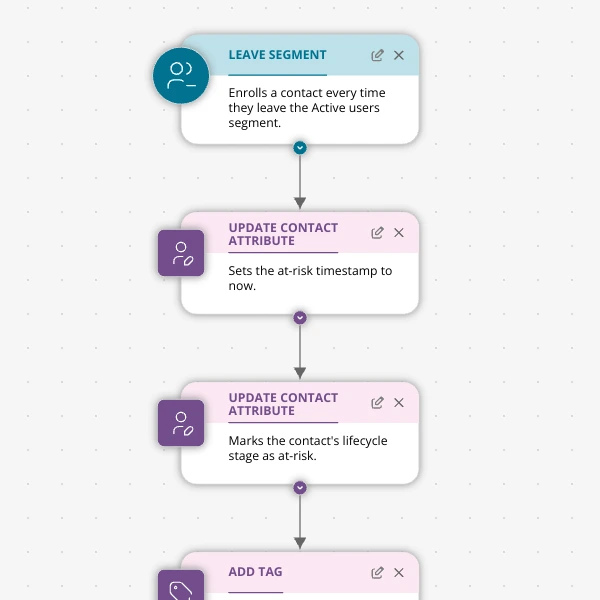
When Active Users Go Dark: A 4‑Touch Win‑Back Journey For Your Shopify App
A detailed, node-by-node Spreeflo journey for winning back previously active Shopify app users who stop engaging, using segment-based triggers, conditional logic, and a four-touch email plus internal alert sequence to recover usage and MRR.