Stop Guessing Who Will Churn: Build a Renewal-at-Risk Early Warning for Your Shopify App
This playbook walks Shopify and e‑commerce app teams through wiring a Spreeflo journey that turns usage, support, and milestone signals into a renewal-at-risk alert, then drives internal notifications and focused rescue outreach before churn becomes visible.
Industry
Niche
Pattern
Loading sequence...
Three of your highest‑paying Shopify stores churn in the same month. MRR dips, support swears “we didn’t see this coming,” and your churn chart gets a spike that will haunt your next investor update.
If you run a Shopify or e‑commerce app, you’ve probably lived some version of that story. You see app_uninstalled or a failed charge, maybe a salty support ticket, and that’s it. By the time churn is visible, the decision was made weeks ago.
What’s missing is an early, actionable signal that an account is drifting away while you still have time to fix it.
The sequence at the top of this page is the whole journey, end to end. It turns three noisy inputs—usage decline, ticket volume, and missed milestones—into a single “renewal at risk” moment months before the actual renewal. From there, it drives a clean playbook: tag the account, alert your team, and send a focused rescue email while the relationship is still saveable.
In this article, we’ll walk through that journey node by node and show how a small team like our fictional app, “CartWizard” (a $90k MRR cart recovery app on Shopify), wires this into Spreeflo so they stop being surprised by churn.
The hidden cost of seeing churn only at uninstall
For Shopify apps, churn looks instantaneous: one day the store is paying, the next day it’s not. Behind the scenes, though, there’s a long runway of tiny decisions:
The merchant stops checking reports.
They open more “this isn’t working” tickets.
Key onboarding or success milestones never get completed.
The app becomes “nice to have” instead of “must‑keep at renewal.”
If your automation only reacts to app_uninstalled, you miss that whole decision window. That’s where most lifetime value leaks for e‑commerce apps: not at acquisition, but in the quiet months where nobody notices usage sliding.
The goal of this pattern is simple: aggregate those weak signals into one strong one and treat “at risk” as its own lifecycle stage, with its own automation.
Turning noisy signals into a single “at-risk” moment
Before we talk nodes, we need a clear definition of “at risk” that your system can evaluate.
For CartWizard, the team chose:
Usage decline: Key features (recovery campaigns, A/B tests) used far less in the last 30 days than in the 30 before.
Ticket volume: Support tickets opened at least three times in the last 30 days.
Missed milestones: No “success” events like “first recovered order” or “ROI report viewed” in the last 45 days.
Renewal proximity: Annual renewal in the next 90 days, or they’re on a high‑value monthly plan.
They already track events from the app and their support system into Spreeflo using the Spreeflo API. Events look like feature_used, support_ticket_opened, milestone_completed, subscription_renewal_date_updated. Web activity from their admin panel flows through web tracking and analytics.
Those raw events are the ingredients. The journey at the top of this page is the recipe.
Step 1: Define your at-risk criteria in Spreeflo
The entry point for this pattern is a Criteria Match trigger in a journey. This trigger fires the moment a contact newly satisfies your at‑risk definition.
Inside the trigger, you build that definition using Spreeflo’s segment builder:
A renewal window rule on a
renewal_datetimestamp attribute:
-renewal_date is withinthe next 90 days.A usage decline group on a key custom event, say
feature_used:
-feature_used triggered at least 10 times in the last 60 days
- ANDfeature_used triggered at most 3 times in the last 30 daysA ticket volume rule on
support_ticket_opened:
-support_ticket_opened triggered at least 3 times in the last 30 daysA missed milestone rule on
milestone_completed:
-milestone_completed has not triggered in the last 45 daysOptional filters:
- Plan type is “Pro” or higher.
- Store size above a certain GMV or order threshold.
Group these conditions with AND logic so all must be true for the trigger to fire.
Two important configuration decisions on this Criteria Match node:
Re-enrollment: turn it ON.
Accounts can drift into risk, recover, and then drift again. With re‑enrollment on, the same contact can re‑enter this journey later, as long as they’re not already mid‑journey.Scope it to decision‑makers.
In many apps, you have multiple contacts per store. Use your criteria to narrow this trigger to the main owner/admin email, not every user.
At this point, you’ve told Spreeflo: “When someone fits this at‑risk profile, start the sequence.”
Step 2: Flag the account and alert your team
Once the trigger fires, the first few nodes don’t talk to the customer at all. They enrich the contact and wake up your internal team.
Update Contact Attribute – risk status
Add Tag – at-risk renewal
Send Internal Email – early warning
Add an Update Contact Attribute node and point it at a text or select attribute like renewal_risk_status. Configure it to:
Updatethe value to the literal stringat_risk.
Add a second Update Contact Attribute for a timestamp attribute like first_at_risk_at:
Use
Set to nowso you record the exact moment the account first tripped the risk criteria.
These attributes power reporting later and keep the current state visible to support and success.
Next, add an Add Tag node and apply a tag such as at-risk-renewal. Tags make it trivial to pull an “at‑risk” list or trigger other automations later. If you’re new to tags in Spreeflo, the guide on getting started with tags walks through best practices.
Now drop in a Send Internal Email node. Configure it to email whoever owns renewals: the founder, your “customer success” inbox, or a channel that creates tickets.
The internal email should include:
Store name and plan.
Renewal date.
Last 30/60‑day usage summary.
Last 30‑day ticket count.
A link to the account in your admin.
You can inject those details using the same personalization tools you use in outbound emails. The net effect: your team sees a renewal‑at‑risk alert with enough context to act, without digging.
At this stage in the journey, nobody on the customer’s side has heard from you. You’ve simply turned a noisy data pattern into a clear “this account needs attention” signal for your team.
Step 3: Reach out with a focused renewal rescue email
You don’t want to fire off a customer email at the exact second they tip into “at risk.” That can feel creepy and reactive. Give yourself a small buffer.
Time Delay – short pause before outreach
Send Email – value‑first check‑in
Add a Time Delay node for 1 day. This accomplishes two things:
It gives your internal team a chance to look at the account and add notes.
It ensures you’re not reacting within minutes of a bad support interaction.
After the delay, add a Send Email node. This is the first message the customer sees in this journey, so write it carefully.
A strong pattern for CartWizard looked like:
Subject: “Can we make CartWizard pay for itself before your renewal?”
Body:
- Acknowledge their upcoming renewal window.
- Share one or two specific wins they’ve had historically (e.g., “You recovered $12,400 last quarter when campaigns were active.”).
- Call out what’s missing now (e.g., “We haven’t seen a new recovery campaign in a few weeks.”).
- Offer a concrete next step: a 15‑minute optimization call, or a 3‑step checklist they can follow themselves.
Use our email builder to design this once with a layout that surfaces numbers, ROI, and a clear call‑to‑action. Then let the journey reuse it every time an account goes at risk.
Make sure “Send only once” is enabled for this node so the same account doesn’t get the same rescue email multiple times inside a single run.
Step 4: Wait for a health signal, then branch the journey
After you’ve sent the rescue email, the next question is simple: did anything get better?
That’s where Wait Condition and If/Else come in.
Wait Condition – give them time to respond or re‑engage
If/Else – classify outcome
Add a Wait Condition node with:
Condition: a group that expresses “back on track,” for example:
-feature_used triggered at least 3 times in the last 7 days
- OREmail Activity: opened or clicked this rescue email in the last 7 days
- ORmilestone_completed triggered at least 1 time in the last 7 daysTimeout: 7 days.
This means the contact will sit at this step until either they show healthy behavior or a week passes, whichever comes first.
Directly after the Wait Condition, drop an If/Else node with the exact same “back on track” condition.
If the condition is true, they go down the “Recovered” branch.
If false, they go down the “Still at risk” branch.
The reason to re‑evaluate with an If/Else is subtle but important: the Wait Condition moves everyone forward eventually, even if the timer simply expires. The If/Else tells you which of those two scenarios you’re dealing with.
Recovered branch: reset risk and close the loop
On the “Recovered” side, you don’t need a hard sell. You need to quietly reset state and, ideally, thank them.
A simple configuration:
Update Contact Attribute – mark recovered
Remove Tag – clear at-risk marker
Add Tag – credit the save
Send Internal Email – good news
Set
renewal_risk_statustorecovered.Add a Remove Tag node to remove
at-risk-renewal.Optionally, add a tag like
renewal-savedto track this cohort over time.Use Send Internal Email to notify the team that this account looks healthy again, with a quick snapshot of what changed (usage up, milestone hit, etc.).
You can end the journey there for that path. The account will only re‑enter if it falls into the criteria again in the future.
Still-at-risk branch: escalate without spamming
On the “Still at risk” branch, you’ve already sent one thoughtful email and waited a week. The next moves should be higher‑touch, not just louder.
Send Internal Email – escalation
Time Delay – cool‑off before second email
Send Email – direct conversation
Wait Condition + If/Else – final classification
First, add another Send Internal Email node flagged as “High churn risk – manual follow‑up.” This is where a founder or senior CSM can decide whether to:
Reach out personally.
Offer a temporary discount.
Suggest a different plan that better fits usage.
Insert a Time Delay step for 2 days. This respects inboxes and avoids a one‑two punch of rescue emails.
Then add a second Send Email node with a different tone:
Acknowledge that things still don’t look healthy. Ask plainly whether the app is still core to their store. Offer an even more specific next step: a “cancel or optimize” call, or a link to a survey about what’s missing.
This isn’t about pushing them to stay at all costs. It’s about surfacing the truth early, when you can still adjust your product or pricing based on the feedback.
Repeat the Wait Condition + If/Else pair, but this time you might look for:
A clicked link to schedule a call.
A new key feature event.
A reply to one of the emails.
Contacts who still don’t show positive signals after that get routed into a short closing sequence:
Update Contact Attribute
renewal_risk_statustohigh_risk.Add Tag
churn-likely.Optionally, a Webhook action (on the Professional plan) to create a task in your CRM or a message in a “churn‑watch” Slack channel.
Now your team knows: this account is trending toward churn before the uninstall ever hits, and there’s a clear record of what you tried.
What to measure once this is live
Once the journey is running, two metrics matter most:
At-risk-to-renewed rate
Early-detection lead time
Among contacts who enter this journey, how many are still customers 90 days after their renewal date?
Because you tagged at-risk-renewal and recorded renewal_risk_status, you can filter and compare cohorts easily using Spreeflo’s audience tools or by exporting data from platform audiences.
How many days on average between first_at_risk_at and either:
Renewal date (if they stayed), or
The app_uninstalled / churn event (if they left)?
The earlier your detector fires while still being accurate, the more room you have to fix the underlying issues.
You can then tighten or relax your criteria. For example:
If almost every at‑risk account renews happily, your rules may be too sensitive.
If many churned accounts never went through this journey, your rules are too strict or miss certain segments.
Because everything is defined in that Criteria Match trigger and the segment builder, you can iterate without rewriting the whole flow.
Why this kind of automation is a retention moat for small teams
Founder‑led teams often think of automation as a way to send more email. The real advantage is different: it lets you capture rich detail on every customer and act on it in a way that feels personal.
In this pattern, you’re not blasting a generic “please don’t churn” message. You’re:
Watching how each store actually uses your app.
Noticing when that behavior changes in worrying ways.
Routing those accounts through a carefully designed human‑plus‑automation play.
That’s how you stop leaving lifetime value on the table. You build a system once inside build a journey, and it quietly protects your MRR every day, without adding headcount or manual monitoring.
For a Shopify or e‑commerce app, that can be the difference between “we’re constantly surprised by churn” and “we usually see it coming months in advance.” And once you’ve felt the calm of that second world, it’s hard to go back.
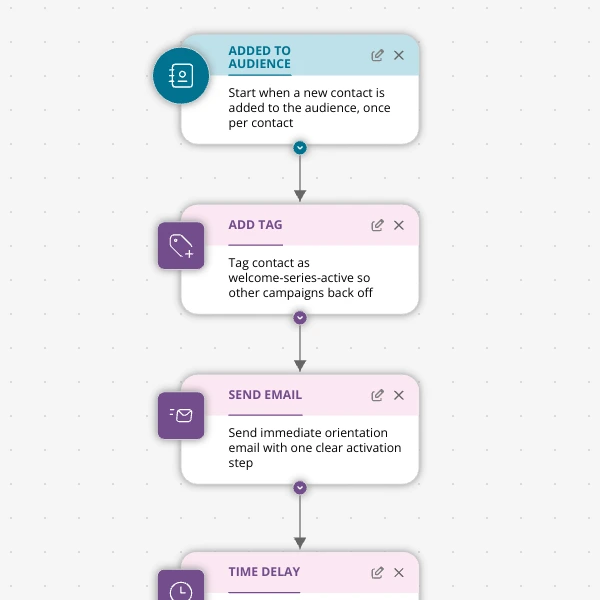
The Shopify app welcome series that turns installs into income
A step-by-step Shopify app welcome email journey for tools like CartSpark, showing how to turn new installs into activated, retained merchants using Spreeflo journeys, tags, and behavioral triggers so fewer trials quietly churn and more trials convert.
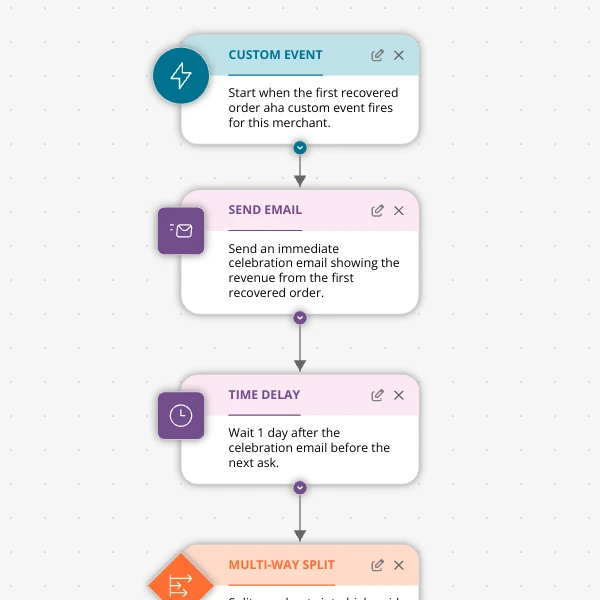
The Aha-Moment Playbook For Shopify Apps: Turn One Magic Action Into Months Of Revenue
A node-by-node playbook for Shopify and e‑commerce apps to center their lifecycle on one aha-moment custom event in Spreeflo, celebrate it, segment merchants by profile and engagement, and turn first recovered value into lasting revenue and retention.
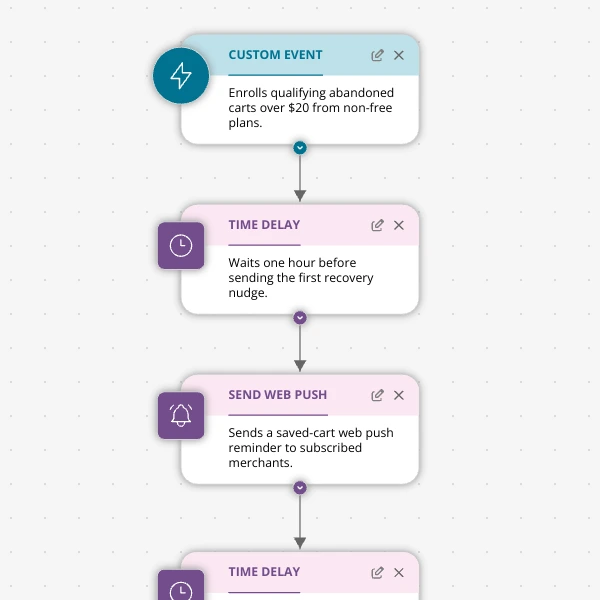
Stop Letting High‑Intent Carts Die: A 3‑Email Recovery Journey for Shopify Apps
A detailed, node-by-node walkthrough of a three-email (plus optional web push) cart-abandonment recovery journey for Shopify apps in Spreeflo, showing how to trigger events, branch on behavior, tag outcomes, and measure recovered carts and revenue.
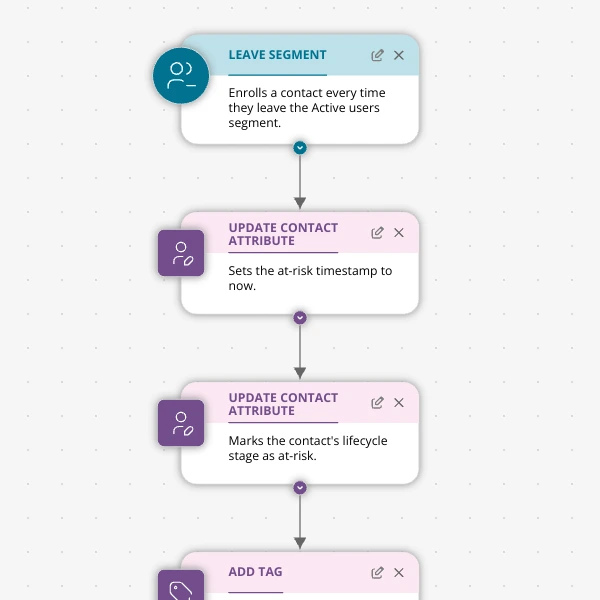
When Active Users Go Dark: A 4‑Touch Win‑Back Journey For Your Shopify App
A detailed, node-by-node Spreeflo journey for winning back previously active Shopify app users who stop engaging, using segment-based triggers, conditional logic, and a four-touch email plus internal alert sequence to recover usage and MRR.